
Transport operators were largely unable to respond effectively to the change in demand caused by Coronavirus because they relied on mechanisms that count the historical number of passengers on services and ticket sales, which do not provide a useful forecast.
This data can't be used to predict future demand – especially throughout a crisis when people are adapting their travel habits to ongoing changes to travel advice. Instead, they need to determine how many people intend to use a particular service, and either try to stagger those journeys or inform passengers of overcrowding in advance and provide alternative options.
“BCRRE researchers have performed a detailed statistical analysis which indicates that Zipabout’s unique crowding predictions, based on passenger intent, provide a good representation of the historic loading data being provided by the rail industry. This confirms Zipabout’s demand data does in fact represent a good proxy measure for actual passenger loading.”
Zipabout’s patent-pending multi-source data platform, which was first developed to support Transport for London in managing crowding during the 2012 Olympics, can provide intent to travel data that points to how busy the transport network will be in future.
Our platform combines static, operational and behavioural data to better predict and manage the flow and capacity of transport networks. It can predict the likelihood of passengers travelling between any two given points.
We do not need to rely on average historical data to determine passengers’ intent to travel, and the technology can be used to warn passengers in real-time if the service they plan on taking is going to be busy or not, and what other services will be quieter.
It is powered by Kx Technology, the world’s fastest time series database which is used by the New York Stock Exchange and Aston Martin Red Bull Racing.
That’s why the UK Government asked Zipabout to power all train operators’ personalised information services and tell all UK rail passengers how disruptions and crowding may affect their journey.
The rail industry asked for a cast-iron guarantee that Zipabout’s crowding data is truly accurate before deploying the service at scale. Zipabout were effectively asked, how can you prove that your predictions will come true?
The only way to achieve that is by correlating the prediction against the outcome. If you have access to both data sets it is a simple validation exercise. In this instance, the prediction is ‘X number of people will be on this train tomorrow’ and the outcome is the exact number of people that actually travelled on that train (historic loading data).
Train operating companies use different methods to determine how many people are on their services. These include manually counting how many people get on and off each train, as well as measuring train load data (how heavy the service is). SouthEastern, which runs train services in London and the South East, made their train capacity information publicly available through DARWIN, the GB rail industry’s official train running information engine, over the summer.
We asked the University of Birmingham’s Centre for Railway Research and Education (BCRRE) to independently validate Zipabout’s data. BCRRE researchers retrospectively took all of Zipabout’s predictions for SouthEastern services over a 30-day period and correlated them with their average loading data.
What they found was a significant correlation between data sources, and they determined that Zipabout’s data is statistically valid.
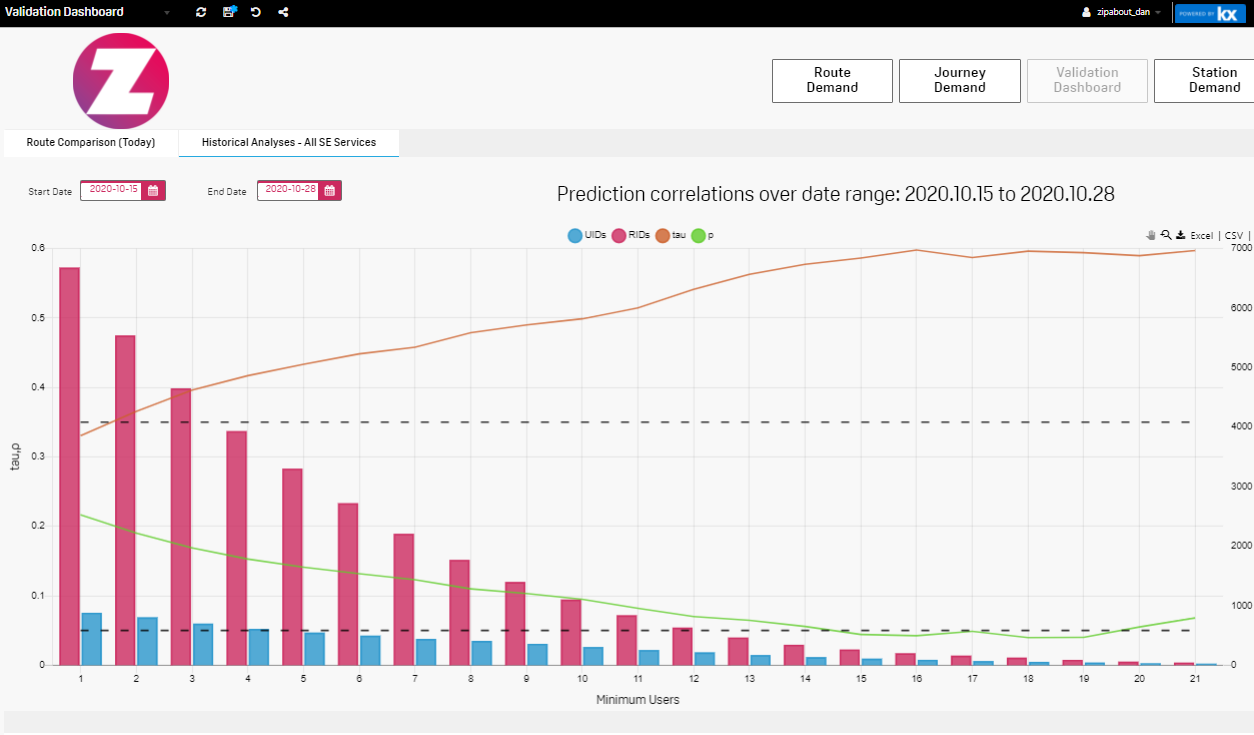
In fact, the university researchers showed that there only needs to be 15 interactions with a train service for us to make a statistically valid prediction of how busy that service will be in the future. When you consider Zipabout’s multi-source data platform was collecting over 20 million interactions every month before the Coronavirus crisis, 15 interactions per service is tiny - it means we can apply this statistical model to more or less every train service in the country and be confident that it is valid.
Having validated our data, we have proven we are able to determine how busy a service will likely be – for example, more people than usual plan on taking the 9am train on Monday.
.png)
Now that Zipabout’s data has been robustly validated, in partnership with leading academics from the University of Birmingham, we can accurately deliver crowding data for the entire UK rail network.
We can tell passengers in real-time how busy their train is going to be in advance of their journey and update them should more passengers later plan on using the same service. This isn't just good news for planning (with our without Coronavirus), it also enables a whole new level of customer service and care for travellers who need to avoid busy or confusing environments, or like to travel at quieter times - something the rail industry in particular is keen to promote and support.
We are also using our technology and multi-source data platform to power a delay prediction programme in partnership with the Rail Safety and Standards Board. Earlier this year we won an RSSB Data Sandbox+ competition (co-funded by Network Rail) which sought to fund demonstrators and feasibility studies that explore data-driven approaches to operational performance challenges.
Zipabout's project is focusing on dynamic and flexible data-driven approaches to delay prediction. This includes using real-time machine learning models to deliver personalised information to passengers that can help to intelligently spread passenger load across the network and minimise the impact of incidents.



